The Case for Local AI Models
NativeLLM Dev Meetup, Buenos Aires, July 2025
For the last couple of years, I’ve been quietly obsessed with small, local AI models. Not the trillion-parameter behemoths we access through the cloud—but lean, fast, efficient models that run on devices you already own. At the recent NativeLLM Dev Meetup in Buenos Aires, I finally had the chance to share that obsession.
This post is a recap and expansion of that quick 15 minute talk—why I believe local models matter, how far we’ve come, and what this means for the future of AI development.
Cloud AI Is Overkill for Most Use Cases
We’ve grown too comfortable reaching for curl to interact with remote LLM APIs. And sure, the results are impressive—but for many tasks, it's like firing up a rocket to cross the street.
Summarizing a paragraph, parsing a JSON payload, classifying an email—these don’t need GPT-4-level compute. Yet every API call routes through cloud infrastructure powered by 1T+ parameter models.
That’s massive overkill.
A Simple Premise: You Don’t Need the Cloud
Let’s start with the basic challenge that shaped this talk:

The assumption that great AI experiences require remote infrastructure is outdated. Local models can deliver excellent performance, and they come with serious advantages:
- Latency: No network hop. Local inference is instant.
- Cost: Once downloaded, inference is free.
- Privacy: Your data never leaves the device.
- Simplicity: No infra, no API keys, no vendor dependencies.
- Reasoning: For many real-world cases, local models are already “good enough.”
You can’t beat the speed of light—and you shouldn’t have to pay per token for tasks your phone can handle in milliseconds.

Distillation: Small Models, Big Brains
So how can small models compete? One of the answer lies in distillation—a process that transfers the “knowledge” of a large model (like GPT-4) into a smaller, more efficient one.
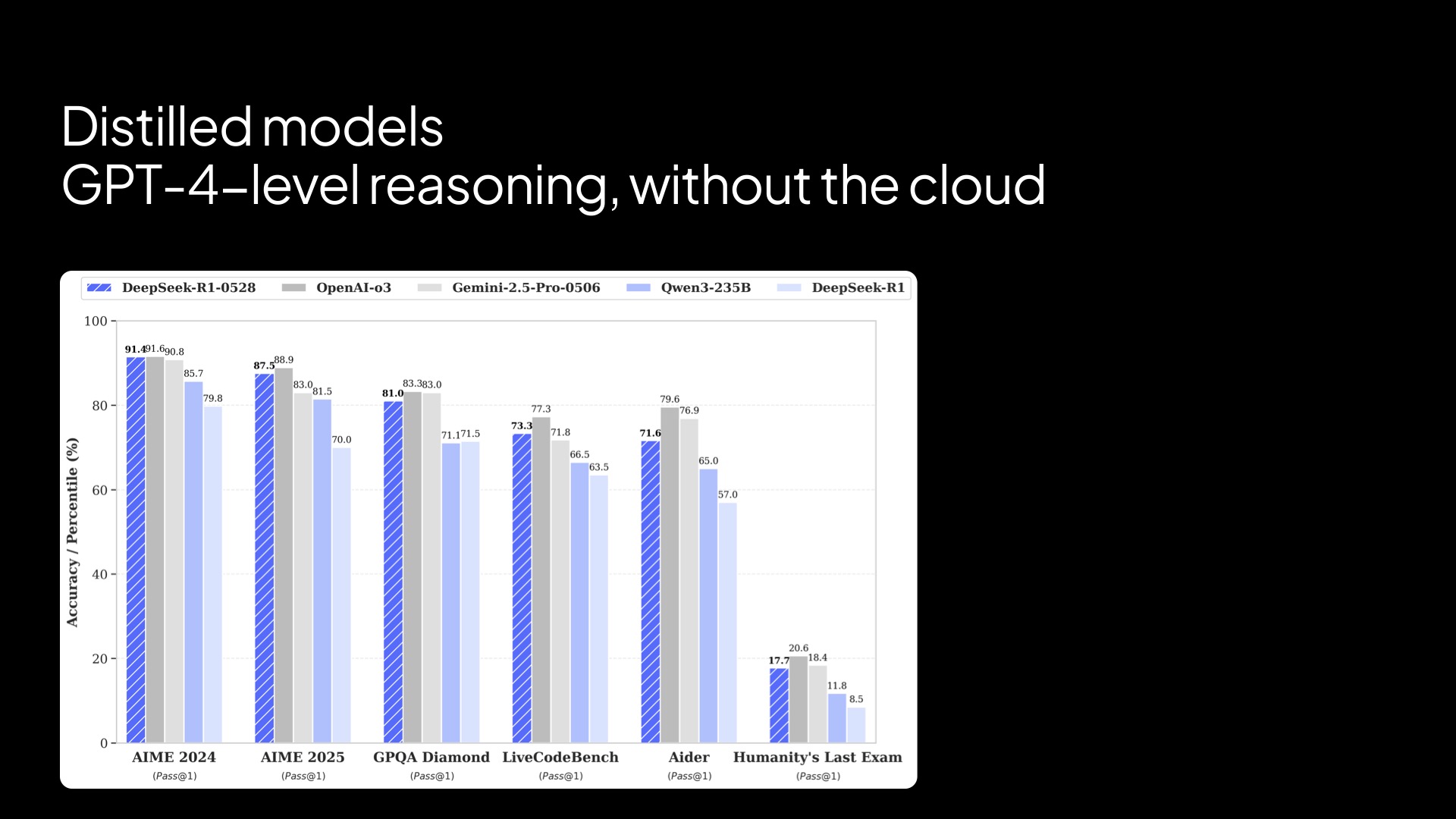
Models like DeepSeek-R1 have distilled GPT-o1-level reasoning into just 7 billion parameters. And the results are surprising: solid performance on tasks like reasoning, summarization, and entity extraction. It’s not about matching the biggest models—it’s about doing enough, fast and locally.
Demonstrating Capability
To illustrate this, I showed prompts around:
- JSON parsing
- Summarization
- Multi-step reasoning
- Entity recognition





The output quality from local models like DeepSeek-7B was close enough to the cloud that, in most contexts, the difference was negligible. Especially when considering the zero latency, zero cost, and full control you get in return.

Hardware Is Already There
This shift to local AI isn't just about model architecture. It’s about the hardware evolution that’s made it possible.
Take Apple Silicon as an example:
- M4 Max has 40-core GPUs in laptops and even iPads.
- iPhone 16 Pro includes a 6-core CPU and a 16-core Neural Engine capable of 35 trillion operations per second.
- Shared memory model eliminates unnecessary data copies.
- 546 GB/s memory bandwidth an insane amount.
- Foundation Model (3B) from Apple runs natively with no setup, no downloads, and is shared across apps.
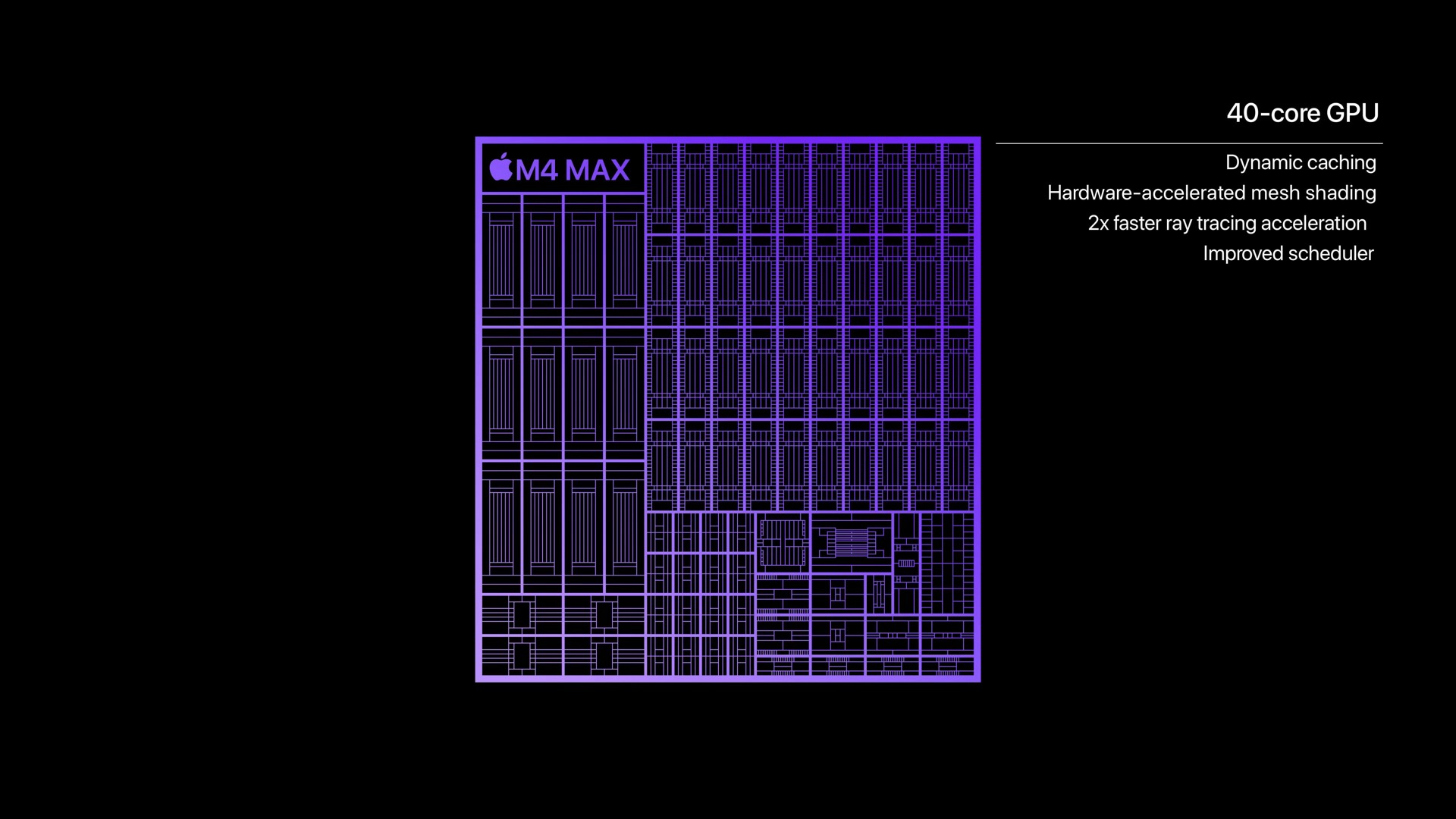

These aren’t theoretical claims—these are shipping devices. The compute is already in your pocket or on your desk.
The Local AI Stack
The software landscape has evolved rapidly to match this new wave of hardware:
Ollama
The simplest way to get started. Run LLMs like gemma3n or deepseek-7b locally with a single command.
Provides a local OpenAI-compatible API, handles downloads, warmups, and runs completely offline.
curl http://localhost:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gemma3n",
"messages": [
{ "role": "system", "content": "You are a helpful assistant." },
{ "role": "user", "content": "Hello!" }
]
}'
I’ve run these models on planes—no internet, no problem.
Apple Foundation Models
At WWDC, Apple dropped a surprise: native, system-level 3B language models baked into iOS and macOS. No downloads, shared across apps, instant inference.
They also shipped SpeechAnalyzer, a built-in speech-to-text framework comparable to Whisper—again, fully local.
MLX
For those who want low-level access and speed, MLX is Apple’s Metal-based inference stack. It supports quantized weights, fine-tuned models, embeddings, and more. I built a CLI tool using MLX that does full inference and retrieval on-device using Qwen3-4B-4bit.
Local Models Enable New User Experiences
With zero marginal cost, we’re entering a new era of UX. Here are a few projects I’ve been working on:
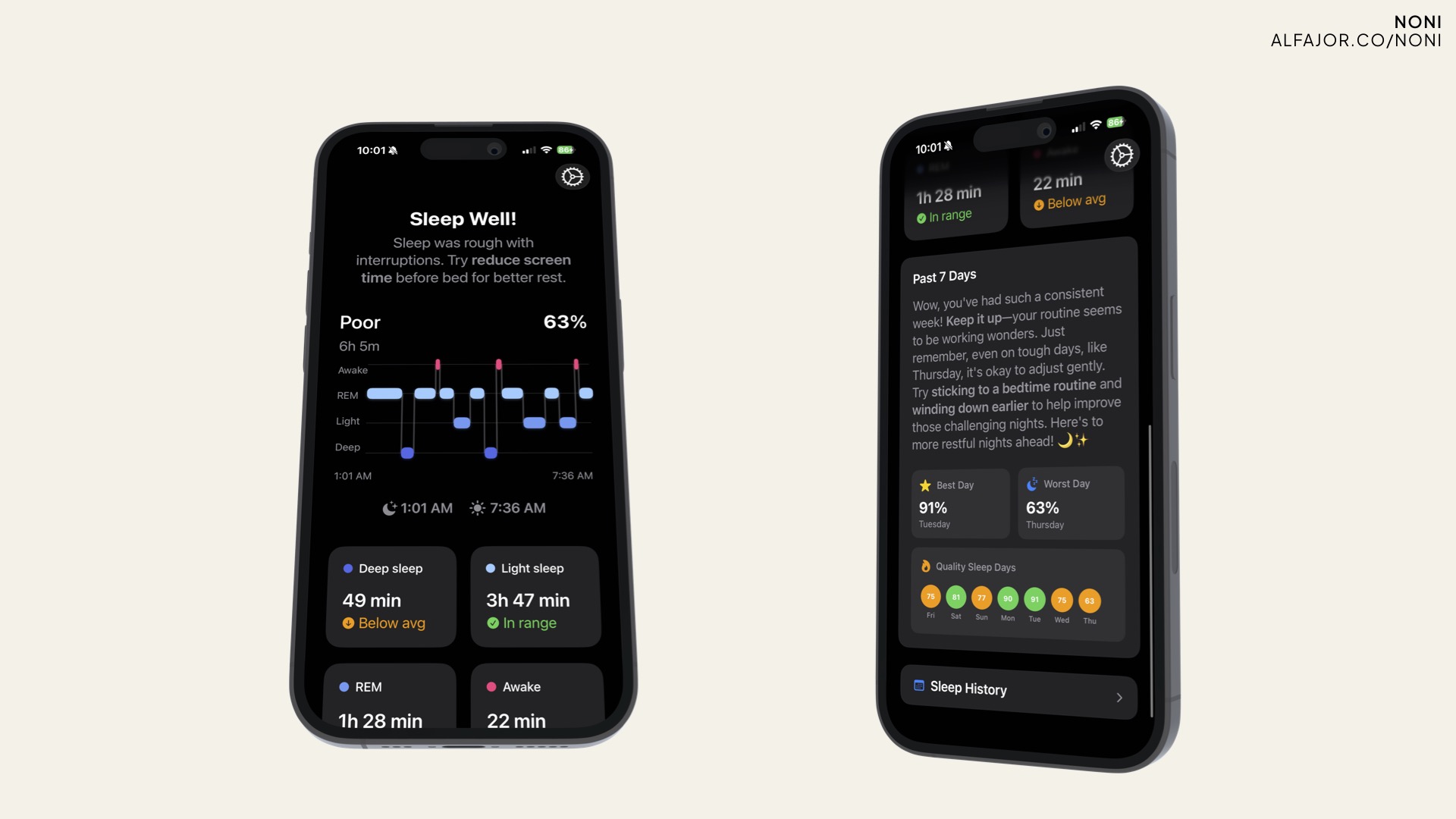
Sleep Coach
On-device coaching app that analyzes your sleep patterns and speaks to you like a real assistant. No backend, no cloud—just your device, HealthKit and the Foundation Model.
Rebound Browser
A browser that turns your web browsing into AI-embedded memory. It indexes, embeds, and stores data locally—so you can ask later, “What did I read about vector databases last week?” via voice commands. Works offline, and keeps your data private.
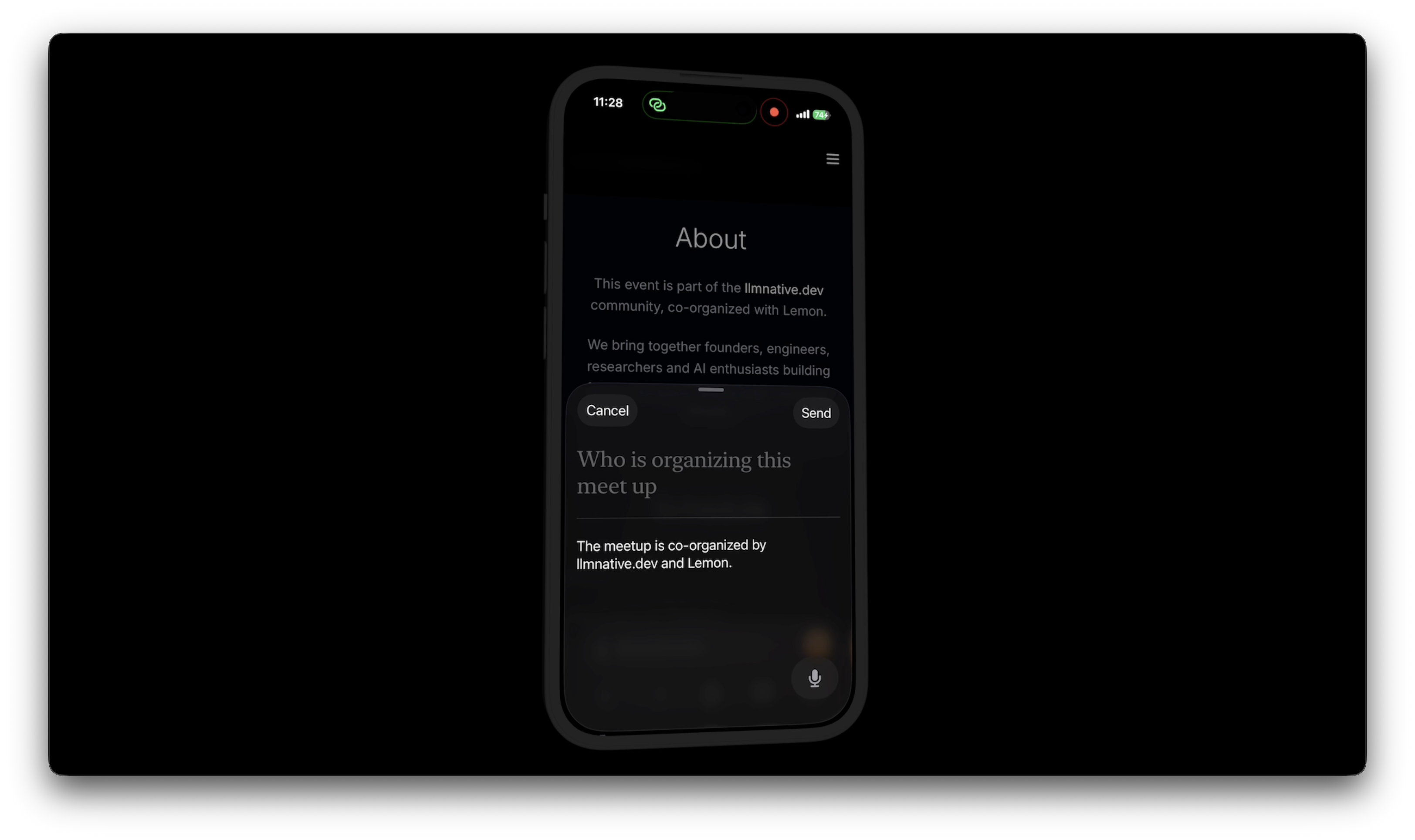
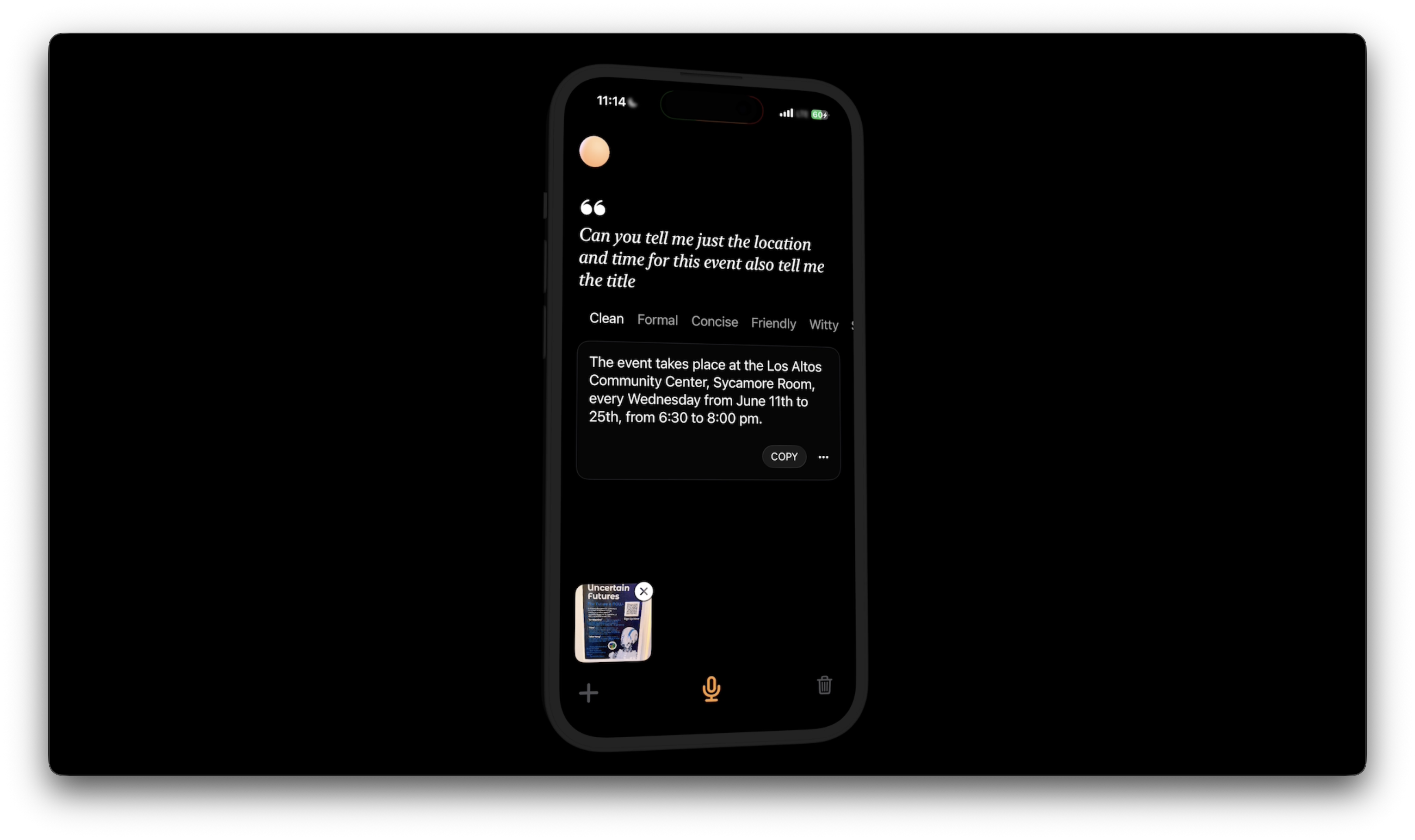
Rebound Assistant
A local speech-driven companion:
- Speech-to-text via SpeechAnalyzer
- Contextual embeddings and inference using Foundation Model
- Slack and clipboard integration
- All local, all private
Why Local Wins
There’s a deeper shift happening here. When inference is free, fast, and local:
- You design differently.
- You build differently.
- You think beyond server costs and API quotas.
And with open licensing (e.g., DeepSeek under MIT), you’re free to build, ship, and iterate without constraints.
This Has All Happened Before
We’ve seen this before.
- Mainframes gave way to personal computers.
- Cloud gave way to mobile-first.
- Now: Cloud AI is giving way to edge-first intelligence.
History repeats. Local models aren’t just a technical curiosity—they’re the next frontier in building software.

Final Thoughts
Local models offer comparable performance for most real-world use cases. The hardware is here. The tooling is here. And the opportunity to design new, unconstrained experiences is wide open.
If you start exploring now, you’ll be ahead of the curve.
Thanks for reading.