Designing Data-Intensive Applications : Chapter 3.1
Ejemplo de una base de datos simple:
db_set () {
echo "$1,$2" >> database
}
db_get () {
# Grep a la key + ‘,’ en el archivo database, luego con un sed reemplaza la key + ‘,’ por nada y se queda con la ultima linea del resultado (por si hubieran duplicados quedarse con el más actual)
grep "^$1," database | sed -e "s/^$1,//" | tail -n 1
}
¿A qué se parece esto? Al WAL que internamente utilizan varias bases de datos.
Si bien esto funciona no escala con un archivo gigantesco.
Important trade-off in storage systems: well-chosen indexes speed up read queries, but every index slows down writes. For this reason, databases don’t usually index everything by default, but require you—the application developer or database administrator—to choose indexes manually, using your knowledge of the application’s typical query patterns.
Hash Indexes
- Riak (cuya version 3.0 se lanzo en agosto del 2020) utiliza un HashMap en memoria con las key y los offset de los values en el archivo donde guardamos el value completo.
- Pensado para un escenario donde tenemos una gran cantidad de lecturas y actualizaciones de una key pero pocas keys diferentes. Ejemplo de contabilizar vistas de un video.
¿Y como hago para no quedarme sin espacio? Vuelvo al concepto de Segmented Log y lo compacto borrando claves duplicadas. Como esto ante una caida llevaría tiempo levantar, en Riak se guardan un snapshot del hashmap en disco para no tener que cargarlo leyendo todo el segmented log.
Observaciones :
-
The merging and compaction of frozen segments can be done in a background thread, and while it is going on, we can still continue to serve read and write requests as normal, using the old segment files. After the merging process is complete, we switch read requests to using the new merged segment instead of the old segments—and then the old segment files can simply be deleted.
-
The merging process keeps the number of segments small, so lookups don’t need to check many hash maps.
-
Es mejor usar binario y no csv.
-
Borrar no es fácil, se usa una linea especial para marcar esto (tombstone, como en cassandra), la cual se utiliza en el merge para descartar datos.
-
Para control de concurrencia se utiliza un solo thread de escritura (tal vez con Singular Update Queue) pero para lecturas como el archivo es solo con appends e inmutable, se puede leer concurrentemente.
-
Muchas de estas cosas se hacen porque tienen una mejora de performance sobre lecturas en discos duros mecánicos, y las escrituras secuenciales sobre discos de estado solido.
SSTables
Las parejas de Clave-Valor se ordenan por clave, a esto le llamamos Sorted String Table, necesitamos que las claves sean únicas en cada segmento.
Ventajas :
- Es más simple y eficiente de mergear, incluso en archivos más grandes que la memoria disponible. Se hace símil mergesort (donde el nuevo segmento ya esta ordenado).
- Ya no es necesario tener un indice de todas las claves en memoria para encontrar una clave en el archivo. Si no tenemos una clave dada en el indice utilizamos otra que si tengamos y partimos desde ahi porque sabemos que esta ordenado el archivo. Utilizariamos un sparse index y no uno completo.
- Como tengo que leer el scan completo desde el indice que tengo, rinde guardar todo lo que hay entre una clave del indice a otra junta y comprimida en disco y la leo toda junta siempre, reduciendo el ancho de banda I/O y el espacio en disco.
A este tipo de estructuras de indexación se las conoce como Log-Structured Merge-Tree, Lucene el motor de indexación de Elasticsearch y Solr, esta basado en este método.
Construyendo y manteniendo SSTables
- When a write comes in, add it to an in-memory balanced tree data structure (for example, a red-black tree). This in-memory tree is sometimes called a memtable.
- When the memtable gets bigger than some threshold (typically a few megabytes) write it out to disk as an SSTable file. This can be done efficiently because the tree already maintains the key-value pairs sorted by key. The new SSTable file becomes the most recent segment of the database. While the SSTable is being written out to disk, writes can continue to a new memtable instance.
- In order to serve a read request, first try to find the key in the memtable, then in the most recent on-disk segment, then in the next-older segment, etc.
- From time to time, run a merging and compaction process in the background to combine segment files and to discard overwritten or deleted values.
Optimización
Un miss es costoso por todo el procedimiento de lectura (memtable y luego todos los segmentos del mas reciente al ultimo) para confirmar que no esta una clave. Para optimizar esto se utilizan Bloom filters (podemos saber con certeza si la clave no esta).
## BTrees
Si alguna vez vieron un Arbol de Búsqueda B (donde tenemos una lista de nodos por nivel y referencias) recordaran esta estructura.
Al igual que las SSTables, los Arboles B mantienen pares de clave-valor, lo que permite búsquedas eficientes, pero ahi termina la similaridad entre ambos. Mientras que en las SSTables tengamos inmutabilidad de los segmentos, solo apendeabamos actualizaciones y luego se borraba en merges, aquí tendremos cambios en los datos.
Aqui se parte la base de datos en pequeños bloques (también conocidos como paginas) de tamaño fijo, de normalmente 4kb, y se escribe o lee un bloque a la vez. Este diseño se correlaciona con el hardware por detrás de los bloques, puesto que los discos también guardan los datos en bloques de tamaño fijo.
{kind=link}
Cada bloque tiene una dirección y un bloque puede referencias a otro (como punteros de memoria en disco) permitiendo crear arboles de bloques/paginas.
Estos arboles están siempre balanceados y su profundidad es muy baja, un árbol de profundidad 4, con paginas de 4kb y 500 referencias por pagina, puede almacenar 256TB. Si bien esta estructura tiene una inserción muy simple, los borrados no lo son tanto.
La escritura en un árbol B implica sobreescribir la pagina entera, como esto en una inserción puede implicar sobre escribir luego al padre con las nuevas referencias, volvemos a ver el concepto de WAL para llevar un log con las operaciones a realizar, permitiendo mantener la consistencia.
Optimización
- En vez de sobre escribir las paginas y mantener un WAL por caídas, algunas bases de datos como LMDB utilizan un schema de copy-on-write. Una copia modificada de la pagina es escrita en otro lugar y luego se crea una nueva referencia apuntando a esta, permitiendo mayor concurrencia.
- Si no guardamos la key completa, sino solo parte de ella, podemos guardar mas keys por pagina permitiendo mayor factor de ramificación.
- Muchas implementaciones intentan mantener “relativamente cerca en disco” las hojas contiguas, para evitar que el disco pierda tiempo.
- Una pagina hoja puede tener referencias a sus hermanos para permitir continuar leyendo de la pagina de su derecha, sin necesidad de volver al padre.
Comparativa
- Las SSTables soportan mayor carga de escritura, puesto que tienen menos amplificación de escrituras que los BTrees.
- La amplificación esta puede acortar la vida de un SSD
- La fragmentación de las paginas de un BTree genera desperdicio de espacio.
- El proceso de compactación de las SSTables puede afectar la performance del sistema, generando picos de tiempos de respuesta, mientras que los BTree mantienen una performance más predecible.
- Si la compactación no esta bien configurada, puede no dar abasto con la tasa de escrituras, y podría llenarse el disco con segmentos no mergeados o empeorar las lecturas al tener que buscar en mas segmentos.
- Normalmente las bases de datos no controlan esto, queda del lado del desarrollador el monitoreo.
- Como la key solo existe en un lugar en el BTree, es mas sencillo ofrecer transacciones fuertes, permitiendo que una transacción quede aislada a un rango de claves en el árbol, y esos lock sean asociados al árbol.
Asociando valores al indice
Tenemos estructuras para guardar nuestra información, en parejas de clave valor, ahora es importante ver que el valor puede ser:
- El valor real (la row, el documento o el nodo de un grafo).
- Tendríamos por cada indice el valor copiado.
- El motor de Mysql InnoDB, utiliza esta técnica llamada indice clusterizado para la clave primaria y luego en los indices secundarios tiene referencias a la clave primaria.
- Un puntero a donde esta el valor.
- Centralizamos el valor en un solo lugar.
Indices multi columna
- Indices concatenados
- Cual guia telefonica.
- Se arma una clave concatenando varias columnas.
- Hay que buscar si o si con la parte izquierda de la clave.
- Indices multidimensionales
-
RTree para información geospacial o búsquedas por rgb.

-
Evitamos tener que buscar por un indice y luego filtrar por la segunda columna los resultados.
-
Si usamos InnoDB, no contamos con esta funcionalidad.
-
Indices fuzzy y búsquedas de texto completo
Los casos anteriores no soportan ciertos escenarios:
- Búsquedas por claves similares (errores gramaticales).
- Sinonimos.
- Claves en desorden.
Lucene (sobre el que se para ElasticSearch) brinda esto, utilizando estructuras como las SSTables para guardar su diccionario de términos, y un indice en memoria que funciona como un trie para optimizar la búsqueda y acotar las SSTables en cuales buscar. Se utiliza un indice invertido, en donde tenemos indexado los términos y a que documentos pertenecen, permitiendo por ejemplo calcular la relevancia de un documento para una búsqueda dada en base a su repetición u otra métrica.
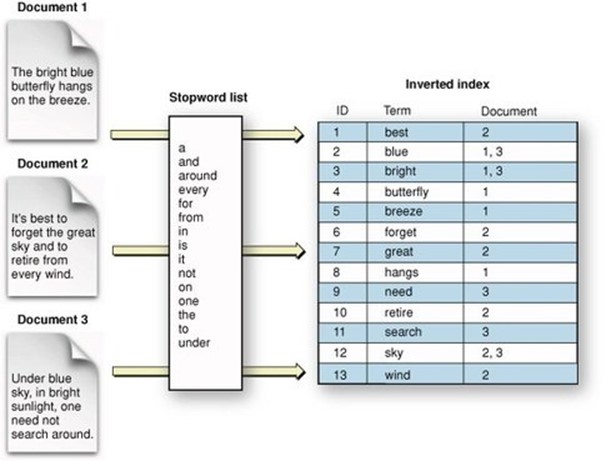
Permiten búsquedas muy rápidas a costa de penalizar las inserciones.
Manteniendo todo en memoria
Si la RAM es cada vez más barata, y muchos casos de uso no tienen tantos datos, porque no tener todo en memoria?
- Memcache
- Redis
- Couchbase
Utilizan alguna escritura a disco para dar durabilidad a los datos (nunca vi una ram con batería pero dicen que las hay), pero su mayor ventaja no esta en que no leen de disco (lo cual si bien suena intuitivo, si había suficiente memoria, el sistema operativo iba a cachear los bloques de disco en memoria de cualquier manera), sino en que no pierdes tiempo utilizando estructuras intermedias para transformar la data en memoria en data en disco.
Se estudian bases de datos que hagan el swap entre memoria y disco mas optimo que el SO y así poder tener mas datos que los que entran en memoria a la vez.