Designing Data-Intensive Applications : Chapter 4
Compatibilidad en 2 direcciones:
- Backward compatibility
- El nuevo código debe poder leer data que fue escrita por el viejo.
- Forward compatibility
- El codigo viejo debe poder leer data escrita por el nuevo.
Formats for Encoding Data
- Representación en memoria, con listas, arrays, arboles, optimizadas para acceso y manipulación por parte del CPU.
- Para enviar la data a un archivo o por la red, hay que encodear a una secuencia de bytes (por ejemplo JSON).
La traducción de representación en memoria a secuencia de bytes se le llama Encoding (o serialización o marshalling) y su reverso Decoding (o parsing, deserializacion o unmarshalling).
Language-Specific Formats
Muchos lenguajes vienen con soporte para encoding ya hecho:
- Java tiene java.io.Serializable pero tambien existen otros como Kryo
- Ruby tiene Marshal
- Python tiene pickle
Esto nos ahorra tener que codearlo nosotros, pero genera algunos problemas:
- El encoding esta muy atado al lenguaje de programación, por lo cual leerlo en otro lenguaje es difícil.
- Vulnerabilidad de seguridad porque al leer una secuencia de bytes se puede instanciar cualquier clase, permitiendo a un atacante presentar bytes para decoding y que se instancia la clase que necesitan para el ataque.
- No presentan soporte para versionado, no están pensadas para brindar facilidad a la hora de dar compatibilidad en ambos sentidos.
- Mala performance, están pensadas para ser fácilmente utilizadas (ejemplo Java serializable vs Kryo).
Conclusión : Mala idea usarlas para algo permanente.
JSON, XML y variantes binarias
Tanto JSON, XML e incluso CSV, son encodings estandarizados, funcionan en multiples lenguajes, permiten el encoding pero además mantienen cierta legibilidad humana y son bastante populares.
Problemas de estos formatos:
- Ambigüedad en los números, XML y CSV no tienen como diferenciar un numero y un string compuesto de números (sin usar un schema externo), JSON distingue estos 2 tipos pero no distingue integer de punto flotante, ni tampoco tiene como especificar la precision del numero. Twitter devuelve el Tweet id 2 veces, una como JSON number y otra como decimal string, dado que Javascript podría pasearlo incorrectamente.
- Si bien soportan bien los caracteres Unicode, no así los strings binarios (secuencias de bytes sin encoding). Para sortear este problema la gente usa un encoding en Base64 (lo cual aumenta el tamaño del dato un 33%).
- Los schemas son opcionales en XML y JSON, si se usan hay bastantes funcionalidades, lo cual es complicado de aprender e implementar. En XML es más común que se usen.
Encoding binario
JSON es menos verborragico que XML pero aun así ocupa mas espacio que los formatos binarios. Esto genero que se desarrollaran muchos encodings binarios para JSON (BSON por ejemplo, que es el que usa mongodb) y para XML (WBXML por ejemplo).
Al no tener un schema, hay que incluir los nombres de los campos en la data encadenada.
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}
Si utilizaremos MessagePack (un encoding binario de JSON) para encodear este objeto, tendríamos lo siguiente:
- El primer byte, 0x83, indica que lo que sigue es un objeto (por el 0x80) y que tiene 3 campos (por el 0x03), en caso de tener mas de 15 campos se utiliza otro identificador de tipo y se usan mas bytes para representar la cantidad de campos.
- El segundo byte indica que lo que sigue es un string (0xa0) y que tiene 8 bytes de largo (0x08)
- Los siguientes 8 bytes son el nombre del campo (userName) en ASCII, no es necesario un carácter de fin puesto que sabemos el largo de antemano.
- Los siguientes 6 bytes sabemos que es un string dado el prefijo 0xa6.
- Repetir hasta el final.
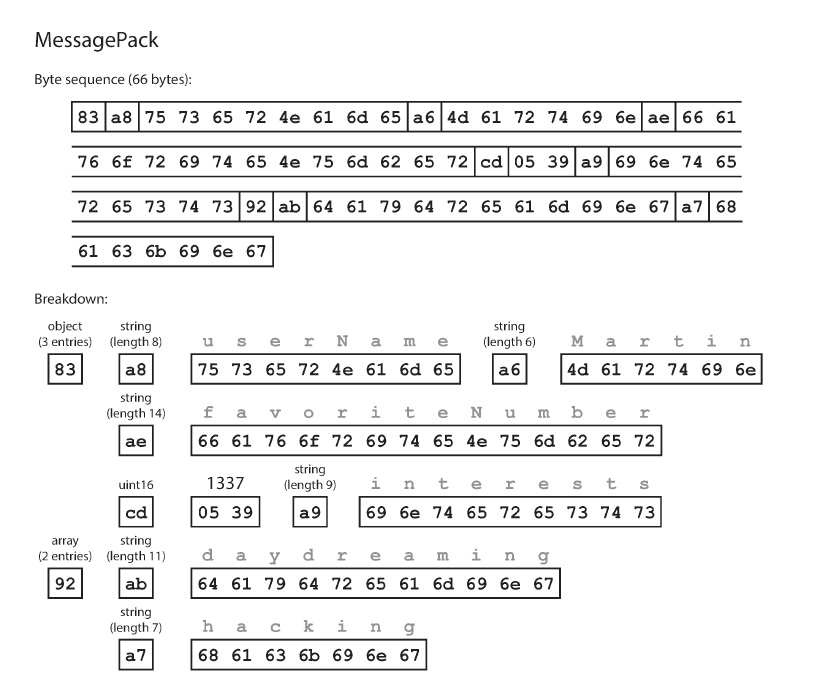
El encoding binario ocupa 66 bytes, mientras que JSON sin espacios en blanco ocupa 81, es una mejora muy menor a costa de perder la facilidad de lectura.
Thrift y Protocol Buffers
Apache Thrift y Protocol Buffers (protobuf) son libraries de encoding binario, la primera desarrollada por Facebook y la segunda por Google, actualmente ambas son open source.
Ambas requieren un schema para los datos que van a ser encodeados. Por ejemplo el ejemplo anterior si tuviéramos que crearle un schema en Thrift (utilizando el interface definition language):
struct Person {
1: required string userName,
2: optional i64 favoriteNumber,
3: optional list<string> interests
}
mientras que en Protocol Buffer se vería así:
message Person {
required string user_name = 1;
optional int64 favorite_number = 2;
repeated string interests = 3;
}
Ambas vienen con un generador de código, que toma la definición del schema anterior, y produce clases que implementen el schema en diferentes lenguajes. La aplicación en la que trabajamos invocará al código generado para las operaciones de encode y decode.
¿Como se ve la data una vez encadenada en este schema? Veamos Thrift con BinaryProtocol:
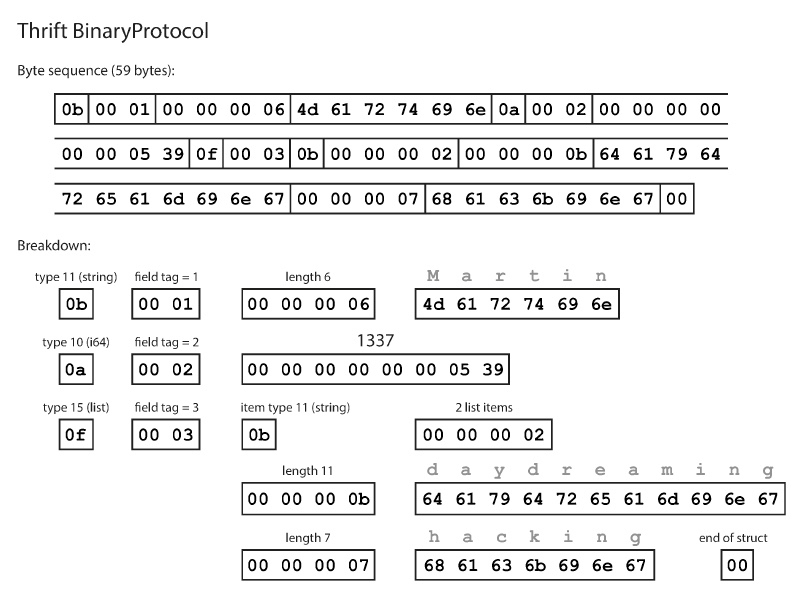
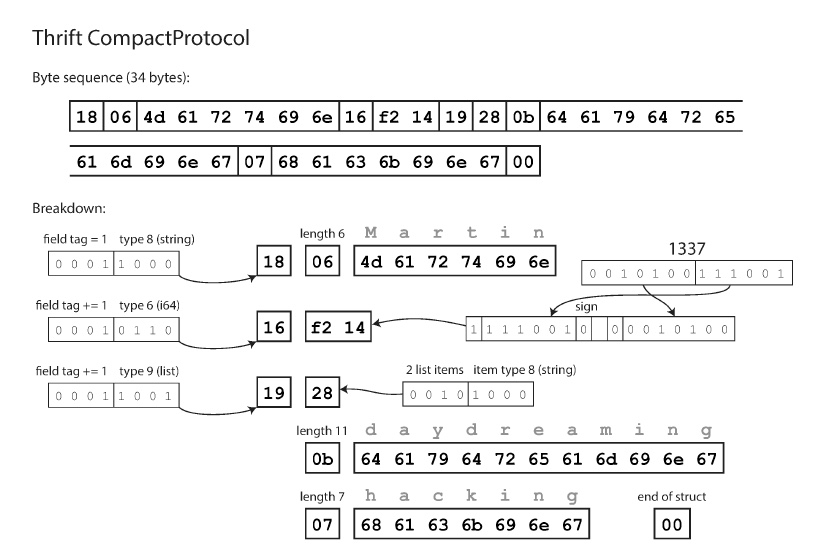
Como se ve no viajan los nombres de campos. Si utilizamos CompactProtocol terminaremos ocupando 34 bytes, esto se logra unificando el byte de tipo de campo y el numerador de campo en un solo byte, además de utilizar integers de largo variable. El 1337, se guarda en 2 bytes separados por ejemplo.
ProtocolBuffer es similar a este ultimo formato de Thrift
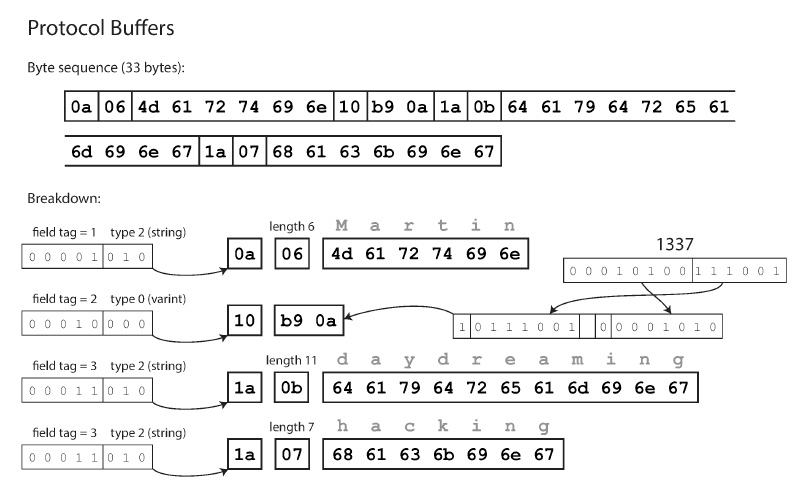
El requerimiento de un campo (o su opcionalidad), no se encodea, es un chequeo en runtime que si el campo no esta cargado luego de deserializar da error.
Evolución del schema
Los nombres de campos pueden cambiar pero no así los numeradores de campo puesto que esto es lo que permite entender el registro encodeado.
Se pueden agregar nuevos campos simplemente usando numeradores nuevos, el código viejo lo ignorara salteándose N bytes según el schema diga. No podremos tener nuevos campos requeridos (sin default value) puesto que no podríamos leer la data antigua.
Se pueden quitar campos, solo si son opcionales y no se puede reutilizar el numerador de campo otra vez.
Según la implementación y el tipo de campo, es posible cambiar de uno a otro.
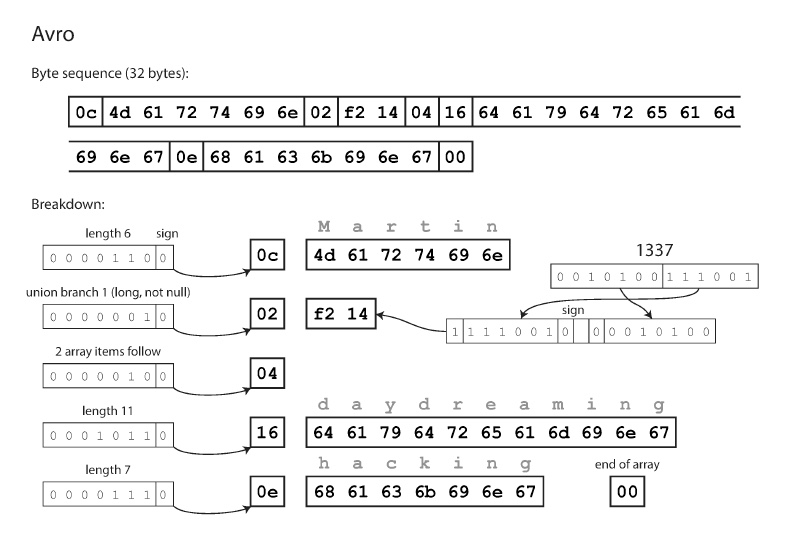
Avro
Surge como Thrift para Hadoop, se compone de 2 lenguajes para generación de schemas, Avro IDL para personas y uno JSON para que lo lean programas. Por ejemplo en IDL seria:
record Person {
string userName;
union { null, long } favoriteNumber = null;
array<string> interests;
}
Mientras que en JSON seria:
{
"type": "record",
"name": "Person",
"fields": [
{
"name": "userName",
"type": "string"
},
{
"name": "favoriteNumber",
"type": ["null", "long"],
"default": null
},
{
"name": "interests",
"type": {
"type": "array",
"items": "string"
}
}
]
}
Al no usar identificadores de campo, el encoding ocupa 32 bytes (el mas compacto de todos), se va recorriendo la cadena de bytes y el schema en orden y se leen los datos que hay en el formato que el schema dice que deberían tener. Esto implica que solo puede funcionar si productor y lector de la data usan el mismo schema.
Diferencias en los schemas
En realidad no precisamos que los schemas sean exactamente idénticos, sino que sean compatibles. Al momento de decodificar la data, la aplicación que esta leyendo le pide a la librería de Avro que haga el match entre los schemas.
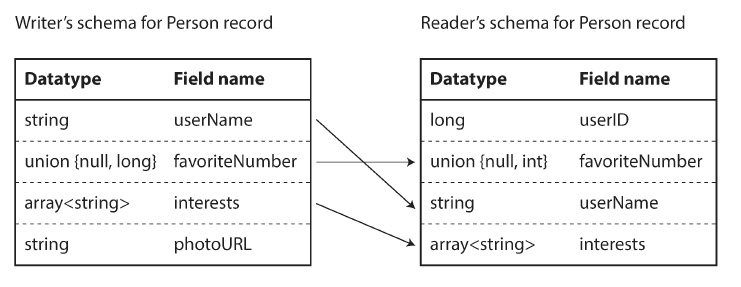
- Si los campos están en otro orden, la librería logra superar esto puesto que busca los nombres de campos en vez de leer en orden.
- Si hay un campo en el schema del productor pero no en el lector, entonces se ignora.
- Si hay un campo requerido en el schema del lector, pero no existe en el productor, entonces se carga con el valor por defecto configurado en el lector.
Reglas para evolución de schemas
- Se pueden borrar y agregar campos si estos tienen un valor por default
- Los valores null solo son soportados de manera funcional, esto es decir declarándolos como una opción.
- No tenemos optional y required
- Se puede cambiar el tipo de datos siempre y cuando la librería sepa convertir de uno a otro.
- Cambiar de nombres los campos es posible pero implica mantener alias en los lectores para poder conocer los nombres que usaba el productor.
Schema del productor
Depende mucho del caso de uso, la manera en la que encontraremos desde los lectores el schema con el que se escribió la data:
- Archivo gigante con muchos registros
- Por ejemplo en Hadoop
- Todos se encodearon con el mismo schema
- Normalmente el productor guarda el schema 1 sola vez al comienzo del archivo
- Avro especifica un formato de archivo para guardar esta data.
- Base de datos con registros escritos individualmente
- Cada registro pudo tener schemas diferentes
- Se guarda un numero de version al inicio de cada registro
- Cuando se lee un registro, se pide a la base de datos el schema con ese numero de version
- Así funciona Espresso la base de datos de linkedin.
- Envio de datos por red
- Se negocia la version del schema cuando se configura la conexión
- Se utiliza esta version por el resto de la vida de la conexión
Generación de código y lenguajes con tipado dinámico
A diferencia de Thrift y ProtocolBuffers no es necesario generar código para poder trabajar con los objetos de Avro. En los casos anteriores esto era importante puesto que en Java, C++ o C# permite la mejora de la performance al usar estructuras eficientes, chequeo de tipos y sugerencias de código en el IDE.
En lenguajes con tipos dinámicos como JS, Ruby o Python la generación de código no tiene mucho sentido dado que no hay compilación, además de que en caso de un schema generado dinámicamente (como un schema de Avro generado a partir de una tabla de la base de datos) no es necesario código generado para acceder a la data.
Los objetos de Avro se pueden abrir con la librería de Avro y empezar a ver la data tal como haríamos con un objeto JSON, los archivos son auto descriptos dado que incluyen toda la metadata necesaria para ser procesados.
Flujo de datos en Bases de datos
En general multiples procesos acceden a la base de datos al mismo tiempo, estos procesos vienen de varias aplicaciones o servicios, o ser instancias del mismo servicio trabajando concurrentemente. Esto genera que sea muy probable que haya diferentes versiones de código en cada instancia en algunas ventanas de tiempo.
Podemos tener:
- Escrituras actuales que luego el proceso de lectura (con la version nueva) tiene que poder leer
- Escrituras actuales que luego el proceso de lectura (en el cual aun no deployamos) tiene que poder leer
- Agregamos un campo al schema, un proceso con la version nueva escribe un valor para este campo. Luego una version vieja lee el registro, lo actualiza y lo vuelve a escribir. Lo esperable seria que el código viejo mantenga el nuevo campo intacto aunque no sea capaz de interpretarlo
Los formatos de encoding que hemos visto soportan estas funcionalidades, pero a veces es importante tenerlo en cuenta en el código de la aplicación. Si lo que traemos de la base de datos, es guardado en un objeto del modelo de la aplicación y luego encodeado y escrito de vuelta a la base, puede ser que se pierda el nuevo campo al traducir del modelo de la aplicación a encoding.
Escrituras y el paso del tiempo
Data outlives code, el codigo va cambiando de version pero la data tiende a mantenerse constante con el paso de las versiones.
Actualizar la data con los cambios de version es posible pero costoso.
En caso de sacar snapshots o dumps de la base de datos, lo normal es que se escriba el archivo en el schema actual por más que este guardado en multiples versiones del schema.
Flujo de datos entre servicios
Tenemos principalmente 2 tipos
- Servicios web
- Rest
- Se basa fuertemente en las funcionalidades de HTTP * De moda en microservicios
- Mucho mas “light” que Soap
- Soap
- Depende mucho de código propietario
- Dificil de usar sin generadores de código
- Poco legible por el humano
- Rest
- Remote Procedure Call (RPC)
- Se intenta simular que llamamos a una función local pero a través de la red
- Obviamente todos los problemas de red y de sistemas distribuidos aplican
- Por timeouts podríamos estar generando multiples solicitudes, salvo que pongamos idempotencia en el protocolo
- Las invocaciones por red no tienen la estabilidad de tiempos que las locales
- Si los parámetros de la función son primitivos es sencillo, pero si son complejos en vez de enviar un puntero de memoria, habra que enviar una secuencia de bytes con algún encoding
- Cliente y servidor pueden estar en lenguajes diferentes, por lo cual las primitivas y tipos de datos pueden no ser iguales
RPC hoy en dia

Por mas de sus desventajas, hay varios frameworks de RPC actualmente usados. Thrift y Avro ya soportan RPC nítidamente, gRPC es una implementación de RPC usando ProtocolBuffers, Finagle es la implementation de RPC usando Thrift que hizo twitter, o netflix tiene Ribbon por poner algún ejemplo.
Codigo del servidor usando Finagle:
import com.twitter.finagle.{Http, Service}
import com.twitter.finagle.http
import com.twitter.util.{Await, Future}
object Server extends App {
val service = new Service[http.Request, http.Response] {
def apply(req: http.Request): Future[http.Response] =
Future.value(
http.Response(req.version, http.Status.Ok)
)
}
val server = Http.serve(":8080", service)
Await.ready(server)
}
Y en el cliente:
import com.twitter.finagle.{Http, Service}
import com.twitter.finagle.http
import com.twitter.util.{Await, Future}
object Client extends App {
val client: Service[http.Request, http.Response] = Http.newService("www.scala-lang.org:80")
val request = http.Request(http.Method.Get, "/")
request.host = "www.scala-lang.org"
val response: Future[http.Response] = client(request)
Await.result(response.onSuccess { rep: http.Response => println("GET success: " + rep) })
}
Los framework actuales hacen explicita la diferencia en que son llamadas “remotas”, por ejemplo encapsulando en futuros o promesas las acciones asincrónicas que pueden fallar. Muchos ofrecen funcionalidades de monitoreo, diagnostico o descubrimiento de servicios.
Si bien los protocolos RPC con encoding binario son más performantes que JSON + REST, este ultimo presenta mas facilidades para experimentación y debugging, así como un mayor soporte multilenguaje y un ecosistema de herramientas mas grande (servidores, caches, balanceados, proxy, firewall, etc).
Por eso REST sigue siendo el dominante en APIs publicas o intercompañías mientras que RPC se utiliza dentro de una misma organización (los mayores generadores de frameworks son Twitter, Netflix, Google, etc).
Evolución y encoding de la data
La compatibilidad de los datos entre versiones en RPC viene heredada por el encoding en el que se basen:
- Thrift, gRPC (basado en ProtocolBuffer) y Avro RPC ya vienen con soporte según las limitaciones que cada formato tiene.
- SOAP utiliza schemas XML en request y response, normalmente esto es suficiente.
- RESTful APIs normalmente usan JSON sin schema, por lo cual es posible agregar parámetros opcionales o agregar nuevos campos a la respuesta. A veces se utiliza la version como parte de la url o vinculada con la api key del cliente.
Flujo de datos con mensajes
En los sistemas de mensajería asincrónica, tenemos un punto intermedio entre los otros 2 universos que vimos. El cliente espera que los mensajes sean entregados al otro servidor de manera rápida al igual que RPC pero ademas tienen en común con las bases de datos que los mensajes no son enviados directamente en una conexion sino que van por un intermediario (message broker, message queue) que guarda temporalmente el mensaje.
Tener un message broker da algunas ventajas:
- Funciona como buffer si el destinatario esta caído o sobrecargado
- Puede implementar reintento de mensajes a un proceso que se rompió
- No es necesario conocer la IP y puerto del destinatario
- Broadcast de mensajes
- Desacoplamiento de emisor y receptores
Ejemplos de brokers son IBM WebSphere, RabbitMQ, ActiveMQ, Kafka, etc.
El funcionamiento es sencillo, se envia un mensaje a una cola o tópico, y el broker se asegura que este mensaje llegue a 1 o mas consumidores/subscriptores de esa cola/topico.
Los broker normalmente no fuerzan ningún modelo de datos, los mensajes son solo una secuencia de bytes con algo de metadata, así que cualquier formato de encoding es valido.
Framework de actores distribuidos
El modelo de actores es un modelo para programación concurrente en un solo proceso, la lógica se encapsula en actores, cada uno representando un cliente o una entidad, pudiendo tener su estado local.
La comunicación entre actores es via mensajes asincrónicos, la entrega de estos mensajes no esta garantizada. Cada actor procesa un mensaje a la vez, así que no necesita preocuparse por hilos y cada actor puede estar coordinado independientemente por el framework.
En un framework de actores distribuidos, este modelo es usado para escalar una aplicación en multiples nodos, utilizando el mismo mecanismo de comunicación sin importar que el emisor y receptor estén o no en el mismo nodo. Si están en nodos diferentes el mensaje sera encodeado en una secuencia de bytes y enviado por la red.
Como el modelo ya espera que haya problemas de red y los mensajes pueden perderse, funciona mejor que RPC en ese sentido.
El framework de actores integra un broker de mensajes y el modelo de programación de actores en un solo lugar. Si se quiere hacer una actualización por nodos de la aplicación es necesario pensar en la compatibilidad de versiones y los mensajes de versiones diferentes que pueden llegar.
- Akka usa la serializacion nativa de java por defecto, que no soporta compatibilidad en ningún sentido, pero puede reemplazarse con ProtocolBuffers si es necesario.
- Orleans busca brindar lo mismo sobre .Net, utiliza un encoding propio que no permite compatibilidad en las actualizaciones, hay que crear un nuevo cluster, migrar el trafico a ese y apagar el viejo. Tambien soporta plugins de serializacion custom.
- Earlang OTP no tiene soporte nativo para migraciones, pero se puede programar transiciones de los datos que están pasando por la app hacia una nueva version.